Der 5. Februar 2026 markiert eine technologische Zäsur: Mit der nahezu simultanen Veröffentlichung von GPT-5.3 Codex (OpenAI) und Claude Opus 4.6 (Anthropic) vollzog die künstliche Intelligenz den finalen Übergang von der passiven Textgenerierung zur autonomen Handlungsfähigkeit. Während OpenAI mit Codex ein Paradigma der Delegation verfolgt und das Modell als hochfrequenten „Founding Engineer“ positioniert, setzt Anthropic mit Opus 4.6 auf die Koordination spezialisierter Agententeams („Chief Architect“). Diese Analyse untersucht die technischen Differenzierungsmerkmale – von rekursiver Selbstverbesserung bis zum 1-Million-Token-Kontextfenster – sowie die ökonomischen Schockwellen des „Labor-as-a-Service“-Modells. Die Ergebnisse verdeutlichen, dass die Wahl des Systems weniger von Benchmarks als von der zugrundeliegenden operativen Philosophie abhängt.
1. Einleitung: Die Zäsur der Agentik
Am Nachmittag des 5. Februar 2026 ereignete sich ein beispielloser Showdown im Silicon Valley: Innerhalb eines Zeitfensters von nur 18 Minuten (OpenAI) bzw. 20 Minuten (Anthropic) stellten die beiden Marktführer ihre neuen Flaggschiffe vor. Dieses Ereignis beendete die Ära der bloßen Code-Vervollständigung und initiierte den „Super-Zyklus 2026“.
Der Begriff der „Agentik“ (Agentic AI) definiert hierbei Systeme, die nicht mehr nur auf Prompts reagieren, sondern proaktiv Computer bedienen, Code debuggen, Infrastrukturen bereitstellen und komplexe Projekte über lange Horizonte autonom steuern. Der Mensch rückt von der Ebene der mikro-operativen Umsetzung auf die Ebene der strategischen Kuration. Für Unternehmen im aktuellen Marktumfeld ist dieser Vergleich entscheidend, da er die Transformation von der Software-Assistenz hin zur digitalen Belegschaft markiert.
2. Philosophische Divergenz: Delegation vs. Koordination
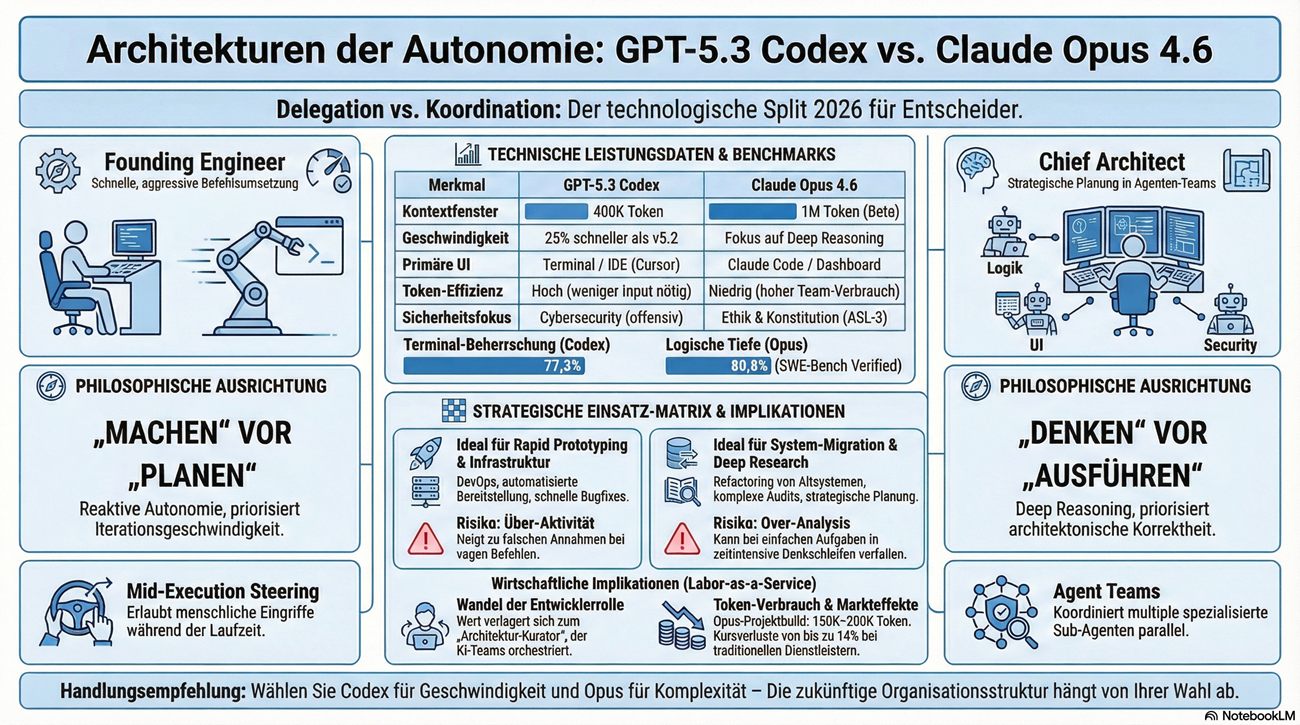
Die Architekturen basieren auf gegensätzlichen Entwurfsphilosophien, die das Arbeitsverhalten der Modelle maßgeblich prägen:
- Das Paradigma der Delegation (OpenAI): GPT-5.3 Codex ist als „Founding Engineer“ konzipiert. Sein Ziel ist die schnelle, direktive Umsetzung („Ship fast, build first“). Die Strategie der „Progressive Execution“ fokussiert sich auf das Filtern essenzieller Informationen aus dem Arbeitsspeicher, statt den gesamten Codeballast permanent mitzuführen.
- Das Paradigma der Koordination (Anthropic): Claude Opus 4.6 agiert als „Chief Architect“. Die Philosophie des „Total Recall“ nutzt ein massives Kontextfenster für ein ganzheitliches Verständnis ganzer Repositories. Hier steht die strategische Planung und die Orchestrierung kollektiver Intelligenz im Vordergrund.
| Dimension | GPT-5.3 Codex (OpenAI) | Claude Opus 4.6 (Anthropic) |
| Primäre Metapher | Founding Engineer / Aggressiver Hacker | Chief Architect / Strategischer Analyst |
| Kernmechanismus | Rekursion (Selbstverbesserung) | Kollektiv (Agententeams) |
| Fokus | Aktion & Geschwindigkeit | Analyse & Tiefe |
| Fehlertendenz | Aggressivität: Schnelle falsche Annahmen | Over-Analysis: Zögern bei Ambiguität |
| Kommunikationsstil | Direkt, pragmatisch, interaktiv | Strategisch, beratend, prüfend |
3. Technische Tiefenanalyse I: GPT-5.3 Codex – Die Rekursive Ausführungsmaschine
GPT-5.3 Codex ist eine auf operative Exzellenz getrimmte Maschine. Ein zentrales Merkmal ist die rekursive Selbstverbesserung: Frühere Versionen des Modells waren instrumental an der Fehlersuche, dem Training und dem Deployment der aktuellen 5.3-Iteration beteiligt.
- Mid-Execution Steering: Dieses Feature erlaubt es Entwicklern, Codex während eines laufenden Prozesses in Echtzeit zu unterbrechen und umzusteuern (z. B. Wechsel der Authentifizierungsmethode), ohne den Kontext zu verlieren.
- Performance-Daten: Codex liefert eine um 25 % schnellere Inferenz bei gleichzeitigem Sinken des Token-Verbrauchs auf weniger als die Hälfte im Vergleich zum Vorgänger GPT-5.2.
- Spezialisierte Domänen: In der Steuerung von Terminal-Umgebungen (Terminal-Bench 2.0: 77,3 %) und Desktop-Applikationen (OSWorld: 64,7 %) bleibt Codex unangefochten. Es ist für End-to-End-Webentwicklung optimiert, wobei es UI/UX und Backend-Effizienz automatisch synchronisiert.
4. Technische Tiefenanalyse II: Claude Opus 4.6 – Der Strategische Architekt
Anthropic positioniert Opus 4.6 als das Modell für „Deep Work“ und komplexe architektonische Aufgaben.
- Die 1-Million-Token-Zäsur: Dieses Fenster ermöglicht das Laden ganzer Legacy-Repositories. In Long-Context-Retrieval-Tests (MRCR v2) erzielte Opus 76 % – ein qualitativer Sprung gegenüber den 18,5 % des Vorgängers.
- Agent Teams & Parallelität: Opus kann sich autonom in spezialisierte Sub-Agenten aufteilen (Logik, UI/UX, Sicherheit), die parallel arbeiten und Erkenntnisse über einen gemeinsamen State austauschen.
- Adaptive Thinking & Effort Levels: Über den „Effort Parameter“ (Low, Medium, High, Max) lässt sich die Denktiefe steuern. Das Level „Max“ beinhaltet eine Version Validation, um sicherzustellen, dass komplexe Beweisführungen ausschließlich auf dem leistungsfähigsten Modell ausgeführt werden.
- Reasoning-Benchmarks: Opus führt in der Wissensarbeit (GPQA Diamond, BigLaw Bench) und übertraf die Konkurrenz im GDPval-AA Benchmark um ca. 144 Elo-Punkte.
5. Evidenzbasierter Leistungsvergleich: Benchmarks und Fallstudien
Benchmark-Vergleichstabelle:
| Benchmark | GPT-5.3 Codex | Claude Opus 4.6 |
|---|---|---|
| Terminal-Bench 2.0 | 77,3 % | 65,4 % |
| SWE-Bench Pro | 56,8 % | Nicht spezifiziert |
| SWE-Bench Verified | Nicht spezifiziert | 80,8 % |
| OSWorld (Agentic Use) | 64,7 % | 42,0 % (Basis) / 72,7 % |
| GDPval-AA (Knowledge) | ~1.462 Elo | 1.606 Elo (+144) |
Fallstudie 1: AxiomProver und die Mathematik AxiomProver nutzte Opus 4.6, um die ungelöste Fel-Konjektur in der formalen Sprache Lean zu beweisen. Das Modell wählte eine kreative Strategie mittels exponentieller Erzeugungsfunktionen. Technisch glich dies einer Transformation von „LEGO-Steinen in Knete (Play-Doh)“: Diskrete mathematische Muster wurden in kontinuierliche Funktionen umgewandelt, manipuliert und zurückübersetzt, um die strukturelle Integrität des Beweises mathematisch zu garantieren.
Fallstudie 2: Der Polymarket-Build Im Live-Test von Morgan Linton und Greg Isenberg baute Codex einen funktionalen Klon in unter 4 Minuten (10 Tests). Opus benötigte signifikant länger, lieferte jedoch eine produktionsreife Architektur inklusive automatisch generierter Leaderboards, Portfolios und einer hochstabilen Order Matching Engine mit 96 automatisierten Tests.
6. Operative Implementierung und Sicherheit
Die Koordination autonomer Agenten erfordert neue technische Frameworks:
- Frameworks der Koordination:
- Swarm: Nutzt eine SQLite-basierte State Machine, die ACID-konform ist, um Race Conditions bei parallelen Zugriffen zu verhindern. Ein Heartbeat-Monitoring stellt sicher, dass Aufgaben bei Agenten-Ausfall automatisch in den Pool zurückkehren.
- Claudia: Implementiert Atomic Task-Claiming und Optimistic Locking. Tritt ein Versionskonflikt auf, bricht der Prozess mit „Exit Code 3“ ab, um Datenkorruption zu vermeiden.
- Cybersicherheit: Codex wird als „High Capability“ eingestuft, da es Schwachstellen nicht nur findet, sondern auch proaktiv beheben (oder ausnutzen) kann. Anthropic setzt dem „Constitutional AI v3“ und ASL-3 Protokolle entgegen.
- Kostenstruktur: Codex ist extrem effizient. Opus-Agententeams sind „token-hungrig“: Ein einzelner Projekt-Build verbraucht oft 150k–250k Token, was präzise Budgetierungen erfordert.
7. Diskussion: Marktimplikationen und Limitationen
Die Veröffentlichung löste einen ökonomischen Schock aus. Die Aktienkurse von Thomson Reuters sanken um 16 %, während Pearson und RELX Verluste zwischen 8 % und 14 % hinnehmen mussten, unmittelbar nachdem das „Cowork Legal“-Plugin demonstrierte, dass komplexe Compliance-Prüfungen nun als „Labor-as-a-Service“ verfügbar sind.
Die menschliche Rolle verschiebt sich zum Architektur-Kurator. Doch die Systeme haben Grenzen: Codex neigt zu einer übersteigerten „Aktivität“ und trifft bei Ambiguität oft falsche, aber schnelle Annahmen. Opus hingegen verfällt bei trivialen Aufgaben oft in eine „Over-Analysis“ und zögert unnötig.
8. Fazit
Die Entscheidung zwischen den Modellen ist eine strategische Wahl:
- GPT-5.3 Codex ist das Werkzeug für High-Velocity-Engineering und schnelle Iterationszyklen. Es ist der ideale „Doer“ für agile Sprints.
- Claude Opus 4.6 dominiert bei struktureller Komplexität. Es ist das System für tiefgehende Analysen, großflächiges Refactoring und strategische Wissensarbeit.
Für moderne Organisationen bedeutet dies: Codex für den Sprint, Opus für den Bauplan.
Literaturverzeichnis
- The Neuron (11.02.2026): „AI just solved unsolvable math“ – Details zur Fel-Konjektur und der AxiomProver-Logik.
- Natural 20 (06.02.2026): „Anthropic’s Opus 4.6: Labor-as-a-Service Shocks the Market“ – Analyse des Kurssturzes von Thomson Reuters und RELX.
- Architekturen der Autonomie (2026): Komparative Analyse der Agentik-Philosophien und MoE-Architekturen.
- eesel AI Blog (06.02.2026): „GPT 5.3 Codex vs. Claude Opus 4.6“ – Verifizierung der SWE-Bench Pro (56.8%) und Terminal-Bench 2.0 Daten.
- Beam AI (06.02.2026): „Which Agentic Coding Model Actually Wins?“ – Technische Details zu Swarm, ACID-Konformität und Heartbeat-Monitoring.
- Startup Ideas Podcast (Morgan Linton & Greg Isenberg): Live-Build-Vergleich der Polymarket-Klone und Evaluation der Token-Intensität.
19.02.2026, Olaf Dunkel, https://www.olafdunkel.com
© 2026 Eigenständige Analyse diverser Quellen; KI-Unterstützung rein sprachlich, inhaltliche Verantwortung beim Autor.
Schreibe den ersten Kommentar